Control-Engine
Introduction
The control-engine package provides two threadpool implementations and helper functions allowing for serial and parallel operations before and after the main function in addition to managed state and the capability to inject tasks anywhere in the chain. Source code is available from hackage[1].
Thread Pools from the Control-Engine Package
Control-Engine was recently released on hackage, providing a simple way to instantiate worker threads to split-up the processing of streaming data. Its was originally developed as a spin-off library from my DHT and I've since generalized it to cover numerous cases.
Trivial Thread Pools
The trivial module Control.ThreadPool can cover static examples; here we will simply count the lines in various files (and hashing them would be just as easy). This example uses only the base packages and Control-Engine:
import Control.ThreadPool (threadPoolIO)
import System.IO (openFile, IOMode(..))
import System.Environment (getArgs)
import Control.Concurrent.Chan
import Control.Monad (forM_)
import qualified Data.ByteString.Lazy.Char8 as L
main = do
as <- getArgs
As you can see below, we simply say how many threads we want in our thread pool and what action (or pure computation, using 'threadPool') we wish to perform. After that its just channels - send input in and read results out!
(input,output) <- threadPoolIO nrCPU op
mapM_ (writeChan input) as -- input stream
forM_ [1..length as] (\_ -> readChan output >>= print)
where
nrCPU = 4
op f = do
c <- L.readFile f
let !x = length . L.words $ c
return (f,x)
And while this does nothing to demonstrate paralellism, it does work:
[tom@Mavlo Test]$ ghc -O2 parLines.hs --make -threaded -fforce-recomp
[1 of 1] Compiling Main ( web.hs, web.o )
Linking web ...
[tom@Mavlo Test]$ find ~/dev/Pastry -name *lhs | xargs ./parLines +RTS -N4 -RTS
("/home/tom/dev/Pastry/Network/Pastry/Module/Joiner.lhs",107)
("/home/tom/dev/Pastry/Network/Pastry/Config.lhs",14)
("/home/tom/dev/Pastry/Network/Pastry/Data/LeafSet.lhs",120)
("/home/tom/dev/Pastry/Network/Pastry/Data/Router.lhs",87)
("/home/tom/dev/Pastry/Network/Pastry/Data/RouteTable.lhs",75)
("/home/tom/dev/Pastry/Network/Pastry/Data/Address.lhs",152)</blockquote>
Control Engine Setup
The thread pools are simple, but what if you need more flexibility or power? What happens if you want to have an up-to-date state shared amoung the threads, or there's a non-paralizable cheap computation you need to perform before the main operation? The answer is to use Control.Engine instead of Control.ThreadPool. The engine provides managed state, numerous hook location, and an abilty to inject information to mid-engine locations.
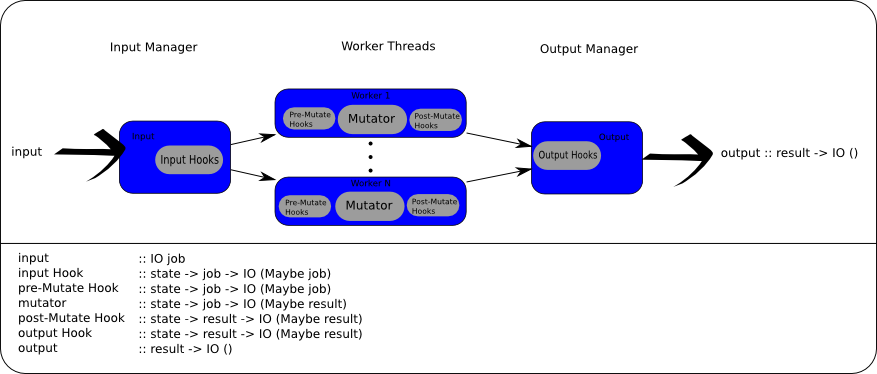
Injectors
The inject* calls can bypass the input hooks (injectPreMutator) or bypass everything besides the output hooks (injectPostMutator) - thus creating a 'result' that had no corrosponding 'job'.
Hooks
Hooks are capable of modifying or filtering jobs or results. All hooks are of type state -> a -> IO (Maybe a); its important to note the type can not change and if a hook returns Nothing then the job or result stops there.
Hooks can either be input, pre-mutate, post-mutate, or output. Input and output hooks are ran in series on all jobs or results respectively; this is intended for low computation tasks that shouldn't be done in parallel later. Pre and post mutate hooks happen on the (parallel) worker threads before and after the main task, called the mutator.
Mutator
The engine consists of N worker threads presumably with the bulk of the work involving running the mutator action on the available jobs. This is the only operation capable of transforming the jobs into the different (result) type.
State Management
Control.Engine was built with the idea that jobs and state reads were frequent while alterations to the state were rare. A design decision was made to use STM to resolve all contention on state alterations and have a manager watch the TVar for change then bundle those changes in a quicker to read fashion (MVar) for the input, output, and worker threads.
The state provided to the hooks and mutator is always consistent but not guarenteed up-to-date. When modifications to the state occur a transactional variable is modified, which wakes the stateManager; in turn, the state manager updates the state IORef which is read by each thread before processing the next job or hook. IORefs are safe as all contention is handled by the STM and the only writer to the IORef is the State Manager.
Web Crawling
Now lets figure out how to help users who need more flexibility using Control.Engine instead of Control.ThreadPool.
MyCatVerbs, from #haskell, suggested a web crawler that uses URls as the job and the mutator (worker) can add all the links of the current page as new jobs while ignoring any URL that was already visited. Lets start!
The imports aren't too surprising - tagsoup, concurrent, bloomfilter and Control-Engine are the packages I draw on.
module Main where
import Control.Concurrent (forkIO, threadDelay)
import Control.Concurrent.Chan
import Control.Monad (forever, when)
import Control.Engine -- Control-Engine
import Control.Exception as X
import Data.BloomFilter -- bloomfilter
import Data.BloomFilter.Hash -- bloomfilter
import Data.BloomFilter.Easy -- bloomfilter
import Data.IORef
import System.Environment (getArgs)
import Text.HTML.Download -- tagsoup
import Text.HTML.TagSoup -- tagsoup
type URL = String
data Job = GetURL URL | ParseHTML URL String deriving (Eq, Ord, Show)
main = do
(nrCPU:url:_) <- getArgs
The library tries to remain flexible which makes you do a little more work but don't let that scare you! It needs an IO action to get tasks and an IO action that delivers the results. Most people will probably just want a channel, but sockets or files would do just as well.
input <- newChan
output <- newChan
Starting the engine is a one line affair. You provide the number of threads, input, output, a mutator function and initial state. In return you are provided with an 'Engine' with which you can modify the hooks and use the injection points.
For this web crawler my 'state' is just a bloom filter of all visited URLs so I'll keep that in the one hook its needed and declare the engine-wide state as a null - (). For the chosen task the mutator needs a way to add more jobs (more URLs) so as pages are parsed any new URLs can be queued for future crawling; this is handled via partial application of mutator funciton.
eng <- initEngine (read nrCPU) (readChan input) (writeChan output) (mutator (writeChan input)) ()
As mentioned, I'll use a bloom filter to keep the web crawler from re-visiting the same site many times. This should happen exactly once for each URL and is fairly fast so I'll insert it as an 'Input Hook' which means a single thread will process all jobs before they get parsed out to the parallel thread pool.
let initialBF = fromListB (cheapHashes nrHashes) nrBits []
(nrBits, nrHashes) = suggestSizing 100000 (10 ** (-6))
bf <- newIORef (initialBF,0)
let bfHook = Hk (uniqueURL bf) 1 "Ensure URLs have not already been crawled"
addInputHook eng bfHook
Finishing up main, we print all results then provide an initial URL. Notice we run forever - there's no clean shutdown in this toy example.
forkIO $ forever $ printResult output
writeChan input (GetURL url)
neverStop eng
where
neverStop eng = forever $ threadDelay maxBound
And from here on we're just providing the worker routine that will run across all the threads and we'll define the input hook. <a href="http://hackage.haskell.org/cgi-bin/hackage-scripts/package/tagsoup">TagSoup</a> performs all the hard work of downloading the page and parsing HTML. Just pull out the <a href="..."> tags to add the new URLs as jobs before returning any results. In this example I decided to avoid any sort of error checking (ex: making sure this is an HTML document) and simply returning the number of words as a result.
mutator :: (Job -> IO ()) -> st -> Job -> IO (Maybe (URL,Int))
mutator addJob _ (GetURL url) = forkIO (do
e <- X.try (openURL url) :: IO (Either X.SomeException String)
case e of
Right dat -> addJob (ParseHTML url dat)
_ -> return () )
>> return Nothing
mutator addJob _ (ParseHTML url dat) = do
let !urls = getURLs dat
!len = length urls
fixed = map (\u -> if take 4 u /= "http" then url ++ '/' : u else u) urls
mapM_ (addJob . GetURL) fixed
return $ Just (url,len)
where
getURLs :: String -> [URL]
getURLs s =
let tags = parseTags s
in map snd (concatMap hrefs tags)
hrefs :: Tag -> [(String,String)]
hrefs (TagOpen "a" xs) = filter ( (== "href") . fst) xs
hrefs _ = []
printResult :: (Show result) => Chan result -> IO ()
printResult c = readChan c >>= print
Filtering out non-unique URLs is just the bloom filter in action.
uniqueURL :: IORef (Bloom URL, Int) -> st -> Job -> IO (Maybe Job)
uniqueURL _ _ j@(ParseHTML _ _) = return $ Just j
uniqueURL bf _ j@(GetURL url) = do
(b,i) <- readIORef bf
if elemB url b
then putStrLn ("Reject: " ++ url) >> return Nothing
else do writeIORef bf (insertB url b, i + 1)
when (i `rem` 100 == 0) (print i)
return $ Just j
Performance
No serious performance measurements have been made beyond extremely expensive (and trivially parallel) problems, so those don't count.