ThreadScope Tour/Spark2
Objectives
Use spark events and the spark size viewer to diagnose a spark granularity issue
Concepts
- rolling buffer strategy - limit the number of sparks created during a traversal by conditioning the creation of new sparks on and old task being completed
Background
In the first module on spark events, we encountered a program that was creating sparks too quickly.
Let's see what happens when we swap out the parallel-everything strategy with a rolling buffer one which creates sparks in such a way that only a buffer-full are in the pool at any time. The list elements are all still evaluated in parallel, but the creation of sparks is throttled by a cunning bit of sequentialness that waits for each successive element of the list to be evaluated (to WHNF) before creating more sparks
parBufferWHNF :: Int -> Strategy [a]
parBufferWHNF n0 xs0 = return (ret xs0 (start n0 xs0))
where -- ret :: [a] -> [a] -> [a]
ret (x:xs) (y:ys) = y `par` (x : ({-x `seq`-} ret xs ys))
ret xs _ = xs
-- start :: Int -> [a] -> [a]
start 0 ys = ys
start !_n [] = []
start !n (y:ys) = y `par` start (n-1) ys
Steps
First improvement: buffering
Build and run the somewhat revised parlist1 example.
./parlist1 +RTS -N2 -lf threadscope parlist1.eventlog
Have a look at the activity log. Notice any changes?
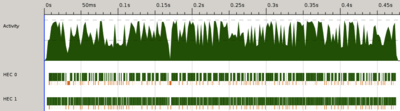
We're getting a bit more use out of that second core now, and seem to be using both of them throughout the life of the program.
Scroll down to the spark creation/conversion for the revised parlist1.
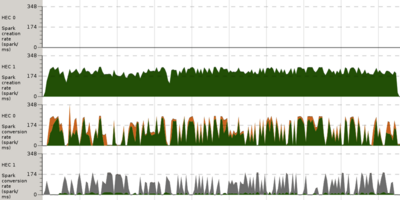
We are now creating and converting sparks throughout the life of the program, which is an improvement.
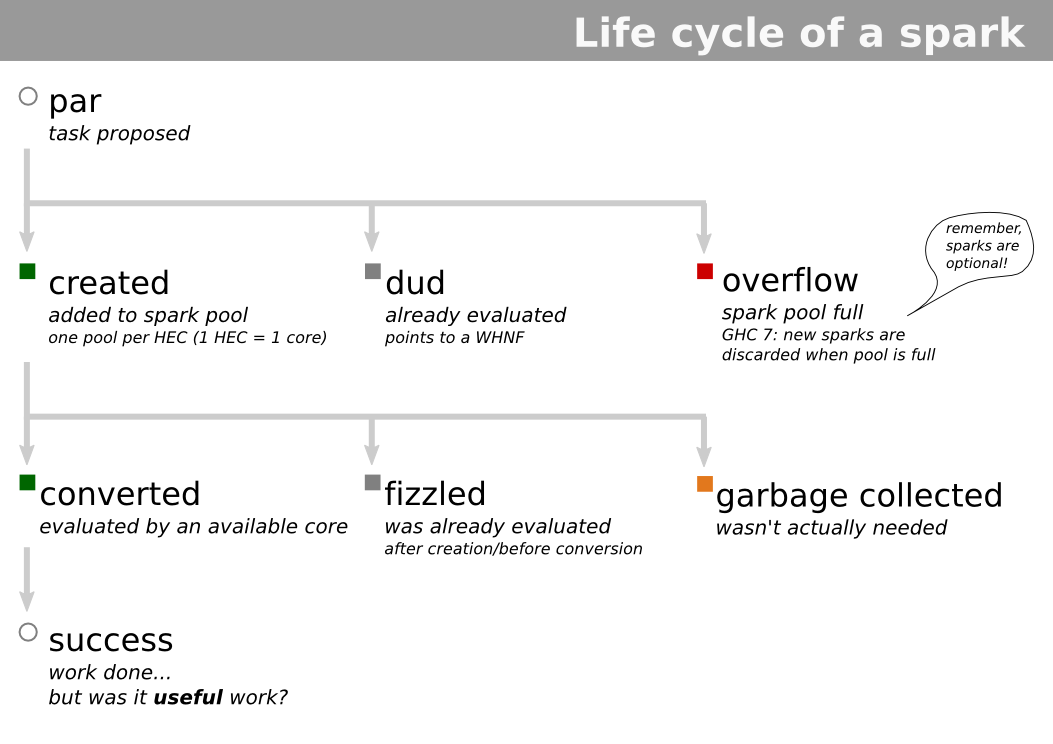
But dig a little a deeper, and notice the colours in the log above. Where is all this fizzle (grey), and garbage collection (orange) coming from? Sparks fizzle if something else has evaluated their task before them.
In this case, the competition comes from the main thread which is trying to consume our list in sum xs. It walks down, evaluating values from the list. The ideal is for the values have already been evaluated by one of the sparks, but since we are getting a lot of fizzle; our main thread must often be getting to these values before the sparks are.
Switch to the spark size view in the bottom drawer.

Notice how most of the sparks being evaluated are rather short lived, around the 4µs range. Maybe we need coarser-grained work so that we don't find ourselves with work that's faster to do than spark off.



Second improvement: tweaking the granularity
Build the parlist2 example and ThreadScope it. This version explores the idea of doing coarser grained work. It feeds bigger inputs to fib, which changes what we're trying to compute (so not a solution for the real world!), but a useful way to explore the possibility of larger sparks.
./parlist2 +RTS -N2 -lf threadscope parlist2.eventlog
Have a look first at the activity
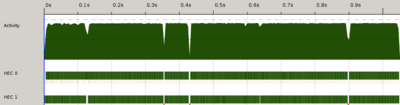
Now we're talking! We're nearly maxing our two cores
Switch to the spark size view

Notice that our sparks are now running for 250 to 500 times longer. Upping the granularity ensures that if the main thread is working on something, it'll be working on something long enough to get started on some of the sparks.
Enable the spark traces and scroll down.
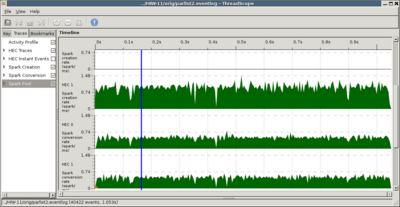
Green everywhere. No more fizzle.



{kind=link}
Exercises
- parlist2 does not compute the same thing as parlist1 because we increased the size of the work to get bigger sparks. Can you think of a way to get the same effect while doing the same task? Validate with ThreadScope.